Install Hadoop using Docker in deb Unix
install Hadoop using Docker in Ubuntu and run your first MapReduce job.

In This article we will be discussing about the installation of Hadoop using Docker in Debian Unix.
There’s genral ways to install Hadoop but that required a lot of configuration and setup. But Docker makes it easy to install Hadoop in your system.
Requirements
- Ubuntu 18.04 or later
- Docker
- 4GB of RAM
- 20GB of disk space
Installation of Docker in Ubuntu
To Get started with Hadoop using Docker in Ubuntu, you need to have Docker installed in your system. If you don’t have Docker installed in your system, just copy and paste the command in terminal
# Add Docker's official GPG key:
sudo apt-get update
sudo apt-get install ca-certificates curl
sudo install -m 0755 -d /etc/apt/keyrings
sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc
sudo chmod a+r /etc/apt/keyrings/docker.asc
# Add the repository to Apt sources:
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/ubuntu \
$(. /etc/os-release && echo "$VERSION_CODENAME") stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt-get update
To install the latest version of Docker, you can use the following command:
sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
sudo apt install docker-compose
once the installtion has done, we can move to step
Installation of Hadoop using Docker
clone the githhub repository
git clone https://github.com/gopalkumr/Hadoop-on-Docker
once you have cloned the repo, Now it’s time to run the docker container using the following command
cd Hadoop-on-Docker
sudo docker-compose up -d
docker container ls
Now you have to copy the namenode folder from cloned repository to the docker container using the following command
go to the cloned repository and run the following command
sudo docker cp code namenode:/
then execute the command to enter into the namenode container
sudo docker exec -it namenode /bin/bash
Now it’s time to create a directory in HDFS using the following command
hdfs dfs -mkdir -p /user/root/input/
hdfs dfs -touchz /user/root/input/data.txt
Now we have to add some content in data.txt file using the following command
echo "The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures.
The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures.
The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures.
" | hdfs dfs -appendToFile - /user/root/input/data.txt
You can verify if the data has added into data.txt or not
hadoop fs -cat /user/root/input/data.txt
if all these steps have completed, Then you can run the MapReduce job using the following command
cd /code/Hadoop_Code
make sure if the wordCount.jar is located at this directory.
if the Wordcount.jar is exist in this directory, you can run the following command to run the MapReduce job
hadoop jar wordCount.jar org.apache.hadoop.examples.WordCount input output
Displaying the output
once the job has completed, you can check the output using the following command
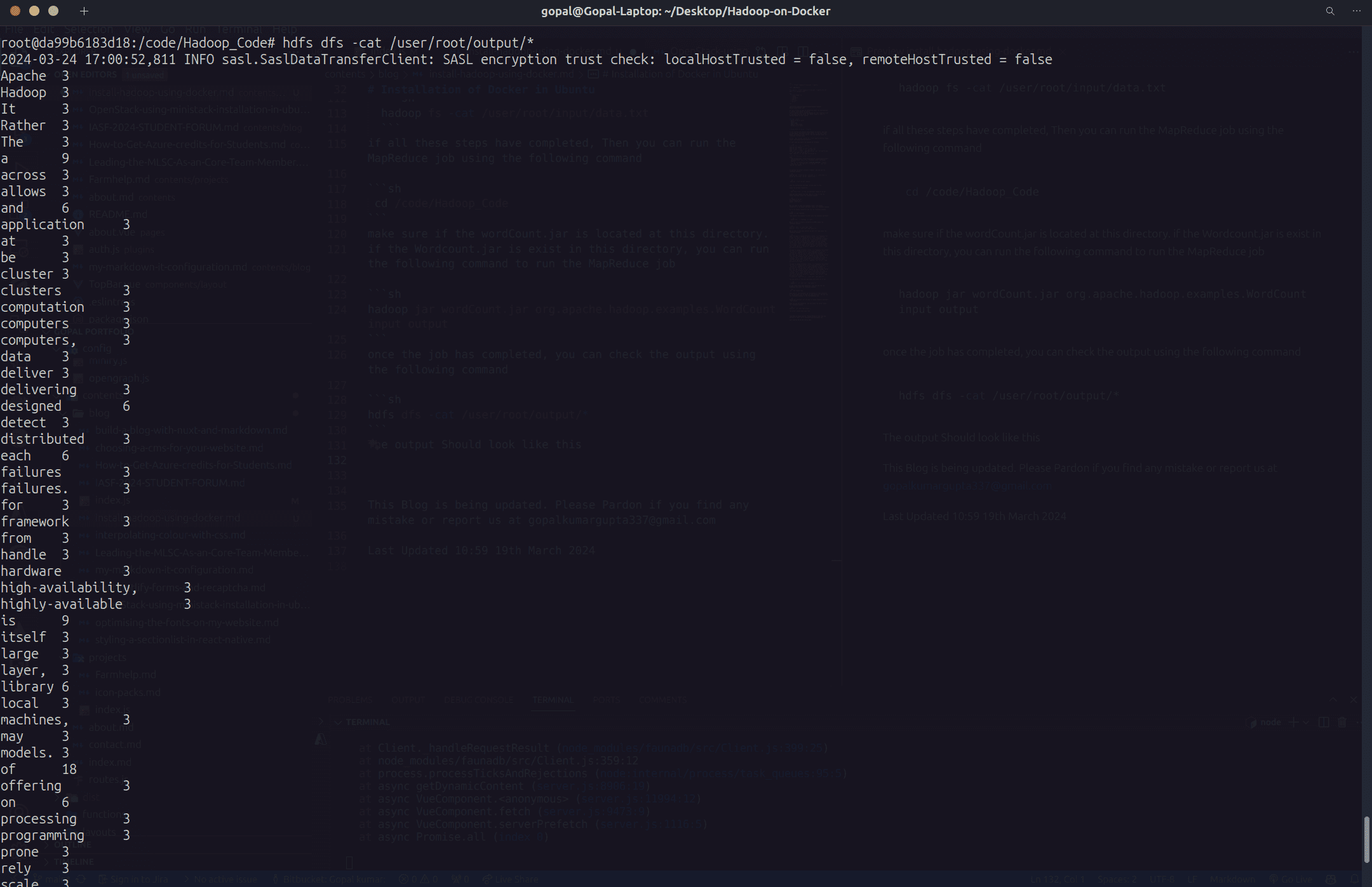
hdfs dfs -cat /user/root/output/*
The output Should look like this
This Blog is being updated. Please Pardon if you find any mistake or report us at gopalkumargupta337@gmail.com
Last Updated 11:59 24th March 2024
0 comments